

OpenAI社のChatGPTを含む自然言語処理を可能とする生成系人工知能(AI)は、世界規模で急速に利用が拡大している。ChatGPTはインターネット上にある膨大なテキストデータを学習して回答を構築するが、医学に関する質問に対して正しい答えを出すよう設計されているわけでない。横浜市立大学循環器・腎臓・高血圧内科学の土師達也氏らは、ChatGPTに医学関連の質問をする際の注意点を科学的に検証。ChatGPTの医学分野における正答率と、インターネット上の総文献数が有意に関連しているとの結果を、Int J Med Inform(2023; 180: 105283)に報告した(関連記事「ChatGPTは医師を凌駕するか」)。
最新モデルの性能は大幅に向上
土師氏らはまず、日本の医師国家試験の過去問題3年分をChatGPTに出題し、正答率と同じ問題を連続して出題した際の回答の一貫率を集計。検討には旧モデルのGPT-3.5と新モデルのGPT-4の両方を使用した。
GPT-3.5モデルに比べ、GPT-4モデルは著しい回答率の向上を認めた(56.4%→81.0%)。回答の一貫率についても大幅に向上していた(56.5%→88.8%)。
その分野のインターネット上の情報量が正答率に関連
ただし、ChatGPTが学習するインターネット上の情報量には分野ごとに差があり、ChatGPTの性能にも影響を及ぼした可能性が考えられる。そこで土師氏らは、試験問題の出題形式(単肢選択問題、多肢選択問題、計算問題)と出題内容(循環器学、小児科学などの医学分野別)に分類し、正答率に関連する因子についてさらに検証を進めた。
インターネット上の情報量の指標として、世界中で刊行された主要な学術雑誌約2万1,000誌が収録されている世界最先端の引用情報データベースWeb of Science Core Collectionに収載された全文献数を集計した。
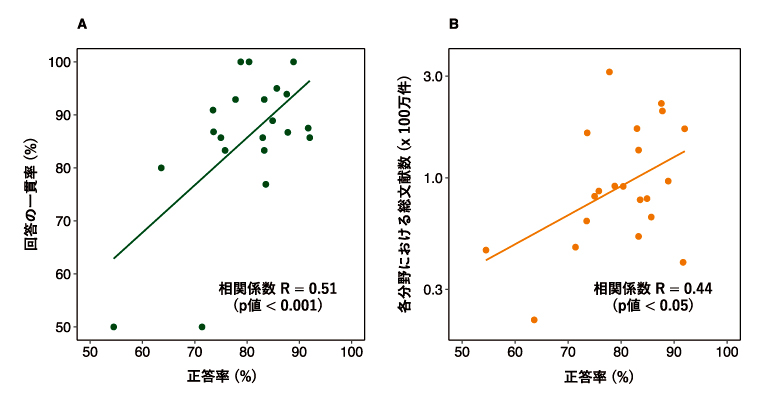
その結果、各分野におけるChatGPTの正答率は、当該分野における総文献数と有意に関連関連しており(R=0.44、P<0.05、図-B)、回答の一貫率と正答率が関連していた(同0.51、P<0.001、図-A)。出題形式と正答率も関連しており、独立危険因子は相対的な文献の少なさだった。
図. 同一問題への回答内容の一貫率と正答率との関係(A)、各医学分野における総文献数と正答率との関係(B)
(横浜市立大学プレスリリースより)
以上から、ChatGPTの性能が当該分野における情報量の格差の影響を受けている可能性が示唆された。
同氏らは「今回の結果は、ChatGPTの回答内容の正確さを判断する一助となることが期待される。医学関連の質問に対するChatGPTの性能と注意点の理解は、医学分野での運用だけでなく、一般市民が日常の医学・保健衛生上の問題解決や知識獲得・教育の促進目的で利用する際にも有用と考えられる」と結論している。
(渡邊由貴)
















